NDB is an in-memory storage engine offering high-availability and data-persistence features.
The NDB storage engine can be configured with a range of failover and load-balancing options, but it is easiest to start with the storage engine at the cluster level. MySQL Cluster's NDB storage engine contains a complete set of data, dependent only on other data within the cluster itself.
The cluster portion of MySQL Cluster is currently configured independently of the MySQL servers. In a MySQL Cluster, each part of the cluster is considered to be a node.
Note: In many contexts, the term “node” is used to indicate a computer, but when discussing MySQL Cluster it means a process. There can be any number of nodes on a single computer, for which we use the term cluster host.
There are three types of cluster nodes, and in a minimal MySQL Cluster configuration, there will be at least three nodes, one of each of these types:
The management node (MGM node): The role of this type of node is to manage the other nodes within the MySQL Cluster, such as providing configuration data, starting and stopping nodes, running backup, and so forth. Because this node type manages the configuration of the other nodes, a node of this type should be started first, before any other node. An MGM node is started with the command ndb_mgmd.
The data node: This is the type of node that stores the cluster's data. There are as many data nodes as there are replicas, times the number of fragments. For example, with two replicas, each having two fragments, you will need four data nodes. It is not necessary to have more than one replica. A data node is started with the command ndbd.
The SQL node: This is the node that accesses the cluster data. In the case of MySQL Cluster, a client node is a traditional MySQL server that uses the
NDB Clusterstorage engine. An SQL node is typically started with the command mysqld --ndbcluster or by using mysqld with thendbclusteroption added tomy.cnf.
Important: It is not realistic to expect to employ a three-node setup in a production environment. Such a configuration provides no redundancy; in order to benefit from MySQL Cluster's high-availability features, you must use multiple data and SQL nodes.
For a brief introduction to the relationships between nodes, node groups, replicas, and partitions in MySQL Cluster, see Section 15.2.1, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”.
Configuration of a cluster involves configuring each individual node in the cluster and setting up individual communication links between nodes. MySQL Cluster is currently designed with the intention that data nodes are homogeneous in terms of processor power, memory space, and bandwidth. In addition, to provide a single point of configuration, all configuration data for the cluster as a whole is located in one configuration file.
The management server (MGM node) manages the cluster configuration file and the cluster log. Each node in the cluster retrieves the configuration data from the management server, and so requires a way to determine where the management server resides. When interesting events occur in the data nodes, the nodes transfer information about these events to the management server, which then writes the information to the cluster log.
In addition, there can be any number of cluster client processes or applications. These are of two types:
Standard MySQL clients: These are no different for MySQL Cluster than they are for standard (non-Cluster) MySQL. In other words, MySQL Cluster can be accessed from existing MySQL applications written in PHP, Perl, C, C++, Java, Python, Ruby, and so on.
Management clients: These clients connect to the management server and provide commands for starting and stopping nodes gracefully, starting and stopping message tracing (debug versions only), showing node versions and status, starting and stopping backups, and so on.
This section discusses the manner in which MySQL Cluster divides and duplicates data for storage.
Central to an understanding of this topic are the following concepts, listed here with brief definitions:
(Data) Node: An ndbd process, which stores a replica —that is, a copy of the partition (see below) assigned to the node group of which the node is a member.
Each data node should be located on a separate computer. While it is also possible to host multiple ndbd processes on a single computer, such a configuration is not supported.
It is common for the terms “node” and “data node” to be used interchangeably when referring to an ndbd process; where mentioned, management (MGM) nodes (ndb_mgmd processes) and SQL nodes (mysqld processes) are specified as such in this discussion.
Node Group: A node group consists of one or more nodes, and stores partitions, or sets of replicas (see next item).
Note: Currently, all node groups in a cluster must have the same number of nodes.
Partition: This is a portion of the data stored by the cluster. There are as many cluster partitions as nodes participating in the cluster. Each node is responsible for keeping at least one copy of any partitions assigned to it (that is, at least one replica) available to the cluster.
A replica belongs entirely to a single node; a node can (and usually does) store several replicas.
Replica: This is a copy of a cluster partition. Each node in a node group stores a replica. Also sometimes known as a partition replica. The number of replicas is equal to the number of nodes per node group.
The following diagram illustrates a MySQL Cluster with four data nodes, arranged in two node groups of two nodes each; nodes 1 and 2 belong to node group 0, and nodes 3 and 4 belong to node group 1. Note that only data (ndbd) nodes are shown here; although a working cluster requires an ndb_mgm process for cluster management and at least one SQL node to access the data stored by the cluster, these have been omitted in the figure for clarity.
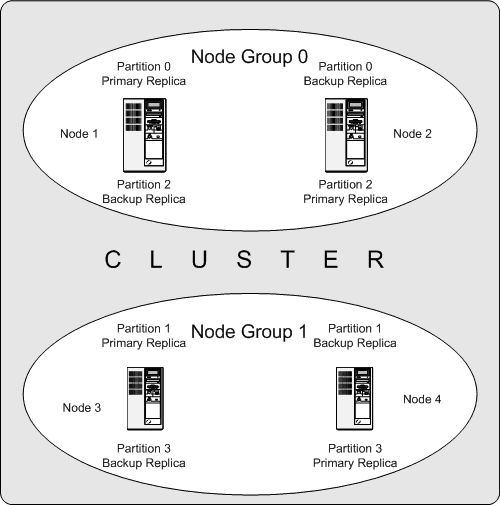
The data stored by the cluster is divided into four partitions, numbered 0, 1, 2, and 3. Each partition is stored — in multiple copies — on the same node group. Partitions are stored on alternate node groups: Partition 2 is stored on .
Partition 0 is stored on node group 0; a primary replica (primary copy) is stored on node 1, and a backup replica (backup copy of the partition) is stored on node 2.
Partition 1 is stored on the other node group (node group 1); this partition's primary replica is on node 3, and its backup replica is on node 4.
Partition 2 is stored on node group 0. However, the placing of its two replicas is reversed from that of Partition 0; for Partition 2, the primary replica is stored on node 2, and the backup on node 1.
Partition 3 is stored on node group 1, and the placement of its two replicas are reversed from those of partition 1. That is, its primary replica is located on node 4, with the backup on node 3.
What this means regarding the continued operation of a MySQL Cluster is this: so long as each node group participating in the cluster has at least one node operating, the cluster has a complete copy of all data and remains viable. This is illustrated in the next diagram.
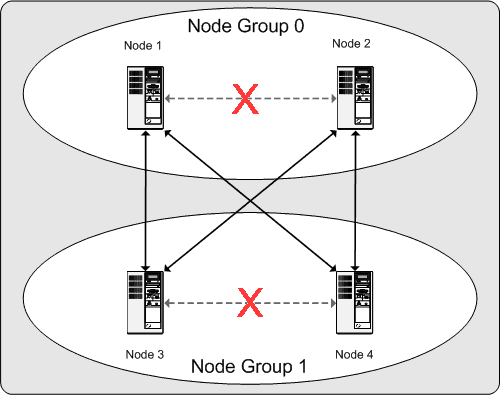
In this example, where the cluster consists of two node groups of two nodes each, any combination of at least one node in node group 0 and at least one node in node group 1 is sufficient to keep the cluster “alive” (indicated by arrows in the diagram). However, if both nodes from either node group fail, the remaining two nodes are not sufficient (shown by the arrows marked out with an X); in either case, the cluster has lost an entire partition and so can no longer provide access to a complete set of all cluster data.