Forwarding Server Voice Topology
In a Microsoft?DirectPlay?voice session using a forwarding server topology, one computer in the session acts as a forwarding server. Each client in the voice session streams voice data to the forwarding server, which then forwards the voice data to all other clients in the session. Each client receives all incoming audio streams forwarded from the forwarding server. Each client's computer then mixes the incoming streams and plays them back.
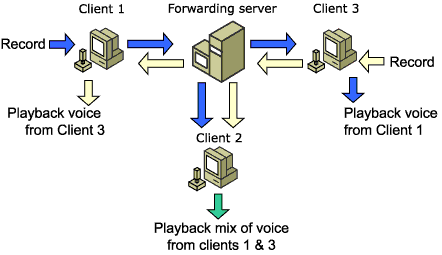
The outgoing bandwidth requirement on each client in a voice session using a forwarding server topology is constant because there is only one outgoing voice audio stream. The incoming bandwidth and processor requirements are identical to the requirements of a voice session using a peer-to-peer topology, but they vary depending on the number of incoming voice audio streams.
The server has much higher bandwidth requirements than the individual clients in a forwarding server DirectPlay voice session. However, the processor requirements are not high because no compression or decompression of voice data occurs on the server. This reduced load on the computer's processor also means that an individual client's computer with a high bandwidth connection can host the forwarding server without adversely affecting the performance of the individual client's computer or the performance of a game server and/or client program running on the same computer.
Note that in a voice session using a peer-to-peer topology, the outgoing bandwidth requirements on the individual clients are usually much higher than the incoming bandwidth requirements. Therefore, reducing the outgoing bandwidth requirement to a single stream of audio can result in a significant reduction in total bandwidth usage. For example, if a client is taking part in an eight-person voice session in which all clients can hear one another, the client has seven outgoing voice streams each time voice data is captured and transmitted on his or her computer. However, it is rare that all clients talk at once, so there are most likely fewer than two or three incoming voice streams at any one time.